AI Medical Record Summarization: The Complete Guide for Clinicians

by Vince Hartman
Nov 25, 2025
This is a deep explainer from Abstractive Health on how AI medical record summarization has evolved over the last 5 years and where it is going as a field.
What is AI Medical Record Summarization
Summarization is a core task of large language models (LLMs). Because of that, the general category of “AI clinical summaries” often gets blurred into “AI medical record summarization” - but they are two distinct concepts.
An AI clinical summary is any use of AI to condense some subset of medical documentation. That can include extractive keywords, building a SOAP (subjective, objective, assessment, and plan) note from a voice transcription, clinical dashboards of records, or handoff note creation. The term has no minimum criteria, the usage is broad, and it’s often used by lower-denominator technology to group themselves into the much harder challenge of a full-record summary.
An AI medical record summary, by contrast, takes a patient’s full medical history - sometimes hundreds of thousands of notes - and condenses the entire chart into a 1-page abstract (~400–800 words) as a longitudinal, sentence-based narrative. Information is excluded only based on clinical salience. If information is excluded because of workflow design (such as encounter-based summaries or handoff notes) then the output qualifies as AI clinical summarization, not AI medical record summarization.
In other words: AI medical record summarization means summarizing the full chart into a clinically meaningful patient narrative.
This type of summarization is particularly challenging because healthcare has never widely adopted a standardized note type for full-record summaries. Before 2023, full-record summaries were only found in malpractice lawsuits, claims processing, or medical research. The closest everyday analog is the Discharge Summary, which summarizes a patient’s recent hospitalization. For patients with long or complicated hospitalizations, writing a robust discharge summary mirrors the art of building a full-record summary. Discharge summaries also include elements of the patient’s life story in the history of present illness. Most good AI medical record summaries inherit some of this DNA.
What makes AI medical record summaries uniquely different is that the clinician reviewing them is often starting with no baseline knowledge of the patient. This is unlike AI clinical summaries, where clinicians are briefly reviewing information they are familiar with. For that reason, an AI medical record summary carries a uniquely higher level of risk compared with other types of AI summaries in healthcare.
Why are AI Medical Record Summaries Uniquely Different From Other Clinical Summarization
Full medical record summarization has rarely been done in healthcare before 2023 because of how large a patient’s record truly is. A single patient can have thousands of pages of documentation across multiple institutions, making it unrealistic for a clinician to manually read and condense it into a single coherent narrative. Instead, clinicians have historically used summarization for temporal events - a visit, a hospitalization, a handoff - and then been left to manually dig through those event-level notes whenever they needed the bigger picture.
The rise of ambient voice-to-text technologies is a good example of summarizing temporal events. These systems use LLM summarization to condense roughly 1,500 spoken words into a ~200-word clinical note. They work well because the context is a 15-30 minute encounter. Temporal reasoning is mostly about recency and historical information is only included if the clinician explicitly says it during the encounter or copies it forward from prior notes. The goal is not to tell the patient’s full medical life story; it’s to accurately capture this one event well enough for documentation and downstream workflows. When history is pulled in, it’s usually in service of a single visit, not a longitudinal understanding. In addition, when a clinician is reviewing a summary from a voice-to-text transcript of a patient visit, they are already familiar with the content since they personally conducted the visit.
AI medical record summarization flips that dynamic completely. Its primary users are often clinicians with no prior knowledge of the patient. Instead of reviewing information they already understand, they are relying on the summary to form their very first mental model of the patient. The purpose of the tool is to bring them up to speed quickly without forcing them to dig through hundreds of thousands of pages of notes. Summarizing a full chart for a clinician with no baseline understanding carries an entirely different level of risk than summarizing an event they personally conducted or are familiar with. In this context, the summary is not just speeding up documentation; it is creating their cognitive map of the patient from scratch. The tool is giving the clinician completely new information, which will shape how they reason, what they look for in the chart, and ultimately how they treat the patient.
Because of that, AI medical record summarization demands a far higher bar for technical architecture, safety controls, and user experience than other forms of clinical summarization. It isn’t a convenience layer on documentation; it’s the starting point for how a clinician understands an unfamiliar patient.
How It’s Done in Practice
In order to build a full medical record summary, you need to pull in data from a patient’s complete medical history. With data fragmentation in the United States, the clinical documentation inside a single electronic health record (EHR) often does not have enough content to support a robust longitudinal summary. The missing pieces live in other hospitals, clinics, and states.
In practice, healthcare data interoperability is coordinated through connectivity to health information exchanges (HIEs). Only a handful of EHRs are deeply integrated into the national HIE frameworks of Carequality, CommonWell, and eHealth Exchange. A big reason for this is historical: EHRs were not required to plug into those national frameworks for their customers to receive Meaningful Use incentives (the federal program that paid providers to adopt certified EHR technology). They were required to be capable of sending and receiving Continuity of Care Documents (CCDs) electronically, but that minimally satisfied local exchange and certification requirements, not true nationwide interoperability.
Large EHRs like Epic, Cerner, and athenahealth chose to build on top of those minimum requirements and productize broader interoperability, but that level of integration came with a higher implementation cost and is more common in large health systems than in small practices. Most of the long-tail EHRs did the bare minimum needed to pass Meaningful Use certification. They can send and receive documents, but they do not automatically pull in a patient’s full outside history in a way that feels like a single longitudinal chart.
For AI medical record summarization, that gap matters. In many EHRs, “integration” is sufficient for temporal stories (recent encounters at that site) but not for building a true longitudinal narrative that spans decades and institutions. As a result, an AI medical record summary either requires:
- the summarization system itself to have direct access to national HIE networks, or
- the user to supply a comprehensive packet of medical records to the system.
Without that broader data layer, what you get is not a full medical record summary; it’s just another local, encounter-based summary wearing a bigger name.
HIEs return data as CCDs, FHIR, and image-based formats such as scans and faxes. Before summarization, the technology stack needs to parse the content into a standardized format so all data is included. As of 2025, a large share of healthcare data in a patient’s medical record is still in unstructured forms like scans, faxes, handwritten notes, and PDFs. While healthcare has made a big push for standardizing electronic documentation so content is easier to parse, a substantial portion of a patient’s record is still in formats where optical character recognition (OCR) technology is required. OCR enables text to be read from images allowing downstream systems to make sense of it.
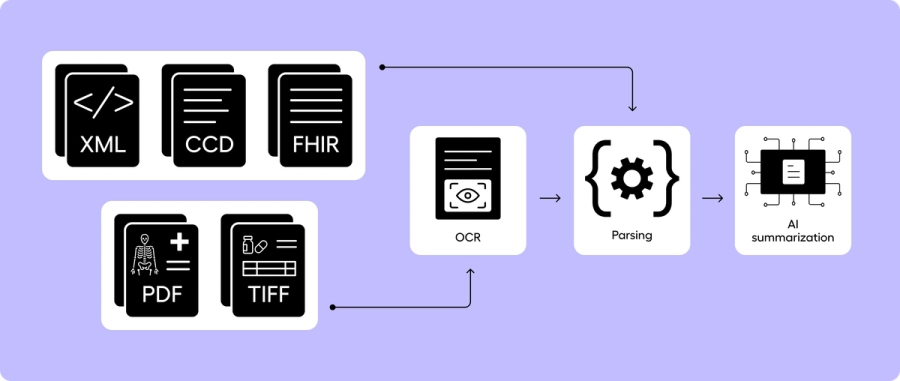
Once all of the text is collated, AI medical record summarization then comes down to model architecture. The three most common architectures are (1) Single-pass long-context / longform summarization, (2) section-to-meta summarization, and (3) RAG-based summarization. Each of these has benefits and drawbacks.
Single-Pass Long-Context / Longform Summarization
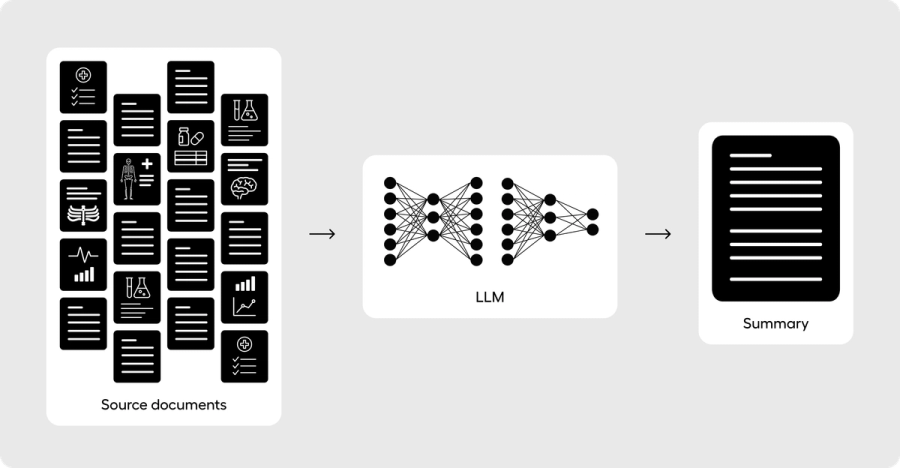
Single-pass long-context / longform summarization is taking the entirety of all of the words and feeding them into the LLM at one time. State-of-the-art LLMs can currently handle up to around one million tokens (hundreds of thousands of words), and so it’s possible in 2025 for the majority of patient medical records to fit entirely into one LLM context window. The largest benefit of a longform architecture is that orchestration is simple - you clean the source notes as much as possible, order them in chronological order temporally, and attempt to consistently feed your notes into the LLM in a predictable manner.
LLMs with the largest context windows include OpenAI’s GPT-5/5.1 (up to ~400k tokens in the API), Anthropic’s Claude Sonnet (up to ~1M tokens in long-context configurations), Google’s Gemini 2.5 Pro (~1M tokens, with larger contexts announced), Meta’s Llama 3.1 (~128k tokens), and Mistral Large 2 (~128k tokens). LLM technology has advanced significantly in the last few years specifically to enable larger context windows to handle domain challenges such as full record summarization.
Some of the drawbacks of longform summarization are that accuracy degrades as the context window expands. Baseline accuracy of top models has been shown to place less emphasis on content in the middle of very large context windows than when fewer tokens are included. Latency also increases because the computational complexity of attention over a larger context window scales roughly O(n²) with the number of tokens. Pushing to very large contexts can make inference much slower and more expensive.
Clinical notes are often highly unstructured, duplicative, and repetitive. If you just feed notes into an LLM without standardization, you are forcing the principal summarization LLM to perform a subtask of parsing and temporal consistency before being tasked with condensing and salience determination. While LLMs are capable of performing all of these tasks, the more tasks you have an LLM do at once, the higher the likelihood that bias and degraded performance will seep into your final result.
Longform summarization in itself also has no source note linking. Once you feed the full content of a chart into an LLM, base models don’t link back where each sentence in the summary originated. And if you prompt or train a baseline LLM to include linking in the output, that output is still inferred based on best-next-word logic; it is not guaranteed to be the actual original linked note. Every out-of-the-box LLM on the market today is not designed to link clinically factual information in a summary back to the original source notes.
It is not clinically safe to build any production-grade AI medical record system without source note linking. Longform summarization is the quickest and lowest-denominator way to build an AI medical record summary, but it is also the surest way to have a high-profile patient safety event – because the doctor has no reasonable way to verify any of the content in the produced summary. It is strongly recommended not to build an AI medical record summarization system by only using a longform strategy.
Section-to-Meta Summarization
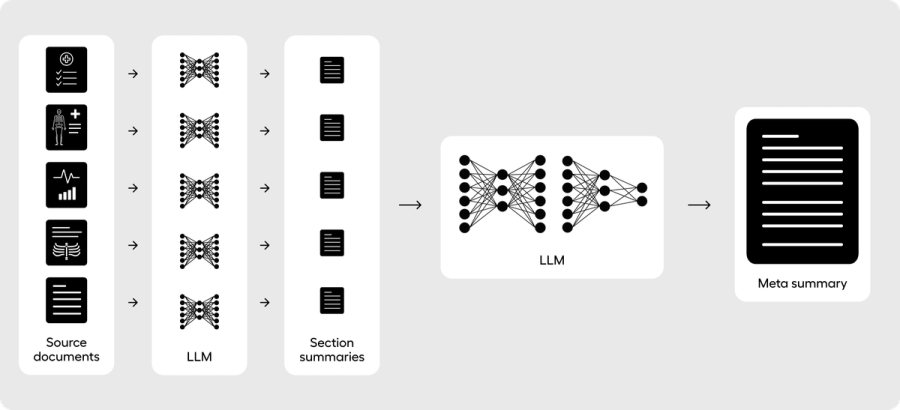
Section-to-meta summarization is performing at least a two-pass pipeline where you first structure and condense individual sections of the full medical record, and then you pass the collection of those summaries into a final meta summarization pipeline to build a comprehensive summary. This pipeline structure has the most academic research to date for creating the longitudinal narrative components of summaries, such as the hospital course section of the discharge summary. This is also the core architecture of Abstractive Health.
By breaking up the full record into individual sections, you can consistently control for the context size of the final pass and ensure that the final summary rarely faces any form of input truncation. For example, if your structure consistently builds section summaries from ~10,000 tokens into a section summary output of ~500 tokens on average, you would condense a ~2M-token chart into 200 sections of ~500 tokens each. When you feed those individual sections into a final meta layer, the input is then ~100k tokens (200 sections × 500 tokens = 100k tokens). You’ve designed an architecture that can consistently handle even the largest context windows of patient records.
You can also ensure that the section components you build are inherently more structured. You design the first-pass LLM layer to consistently compile information such as medical history, labs, vitals, and medications from a smaller pass of information of only ~10,000 tokens. Since LLMs have consistently been shown to perform best at moderate context sizes, you are optimizing for higher levels of accuracy when extracting the base information for your summary.
Because you are condensing the information from sections first, you can architecturally link the content in the final summary back to the source section documents. While baseline longform summarization lacks document-level provenance, a section-to-meta summarization pipeline allows you to embed provenance into the workflow. You are not asking the LLM to “guess” the original provenance - you can build it through rule-based orchestration. The final LLM is then designed to do one task: condense the medical information from the section documents. It is not simultaneously formatting, parsing, or creating temporal linkage; that work is done earlier in the section summaries.
A limitation of a section-to-meta summarization approach is that richer context across documents can be diluted when passing into the final summary LLM. A summary that needs to follow one disease-based theme tightly across the entire record may perform worse with this approach; a RAG-based summarization architecture is better designed for that pattern. Section-to-meta summarization pipelines are best for consistently telling the overall story across all documents.
This architecture is formulated exactly how a clinician would write the hospital course section of the discharge summary. Each day, a clinician will often write one to two sentences that describe the events during the hospitalization. By the end of the patient’s stay, the narrative is assembled into a coherent output where each individual sentence represents the factual content of all the progress notes and other documentation leading up to the final discharge. The goal is to describe the story of the patient while in the hospital from a day-to-day perspective. For an AI medical record summary, whose goal is often to tell the story of a patient’s medical history, section-to-meta summarization is well-suited because it emulates how clinicians have traditionally written the discharge summary.
RAG-Based Summarization
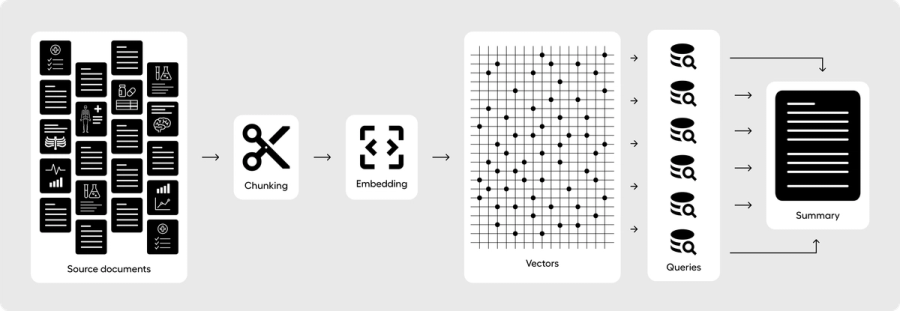
RAG-based summarization is where you first chunk the medical record into smaller pieces (for example, ~1,000-token chunks) and embed those chunks using a vector-based model. You then store the embeddings, chunk text, and relevant metadata in a database optimized for vector search.
Once all the medical documents are stored as vector chunks, you retrieve relevant content as a composition of individual queries. A medical history section, for example, would retrieve top-k chunks for a specific query by searching the vector database for any relevant content. Your orchestration can be designed to have a second pass where you go deeper after the first chunks are returned, drilling into specific diseases or themes that surfaced in the first pass. This multi-layer structure can be designed as a kind of “chain-of-thought,” where your orchestrated LLM is consistently asking itself whether it has found enough context to build a robust summary for just the medical history section.
Once all relevant chunk content has been retrieved, those chunks are fed into an LLM prompt that is designed to build just that one component of the summary. Because you are passing the original chunks into your RAG model, you can link your summary back to the original source documents (or more specifically, to the chunks). Linking individual sentences can be done by having the LLM reference chunk IDs in its output, and you can control for potential hallucinations by validating that only IDs from chunks you actually provided appear in the final summary.
This structure allows you to break up your medical record summary into individual components, and have a RAG orchestration layer answer each one. A RAG-based pipeline could separately handle medical history, allergies, medications, labs, imaging, and so on. The responses produced by a RAG model can be more aligned with each specific question, because the retrieval logic tries to feed the LLM only the most relevant information, rather than a noisy, full-record dump.
The main limitation of this approach is how well your top-k retrieval engine performs. RAG is explicitly designed to limit context to some subset of chunks, which means your summarization architecture becomes heavily dependent on well-structured search logic. Retrieval can become more important than the performance of the LLM itself. If you exclude content during retrieval, the LLM has a 0% chance of including it in the summary because it never saw it. You can try to solve this by increasing k, but as you push k higher and higher, you begin to erase the value of RAG. At some point, you are effectively doing long-context summarization again by feeding most or all chunks into the LLM.
The second limitation is provenance. RAG is designed to provide document-level references to source chunks, but not true sentence-level provenance. Each component summary is still an LLM-produced output, and you cannot trivially track every sentence back to a specific source chunk without extra logic. It is possible to design a RAG-based system that only produces sentences with explicit linkage to chunk IDs, and to enforce that those IDs come from the provided context. It’s just not what vanilla RAG architectures are optimized for.
Finally, RAG as an architecture is best at answering targeted questions, not at telling a patient’s full longitudinal story. The algorithmic backbone is cosine similarity in embedding space, which is fundamentally about “finding chunks that look most similar to this query.” It makes RAG an excellent search engine for finding the most relevant supporting context and assembling it into a response. Often, a good summary does mirror this behavior, but it’s not obvious that this is how clinicians want to consume an AI medical record summary when they have no baseline knowledge of the patient. RAG may place more emphasis on clinically salient patterns and exclude surrounding context in ways that change clinical inference. To date, RAG has not been robustly studied for full medical record summarization, so we don’t yet know how well it aligns with clinical adoption and patient safety at scale.
Just because a system can create an AI medical record summary from a full chart does not mean the type of summary it produces is appropriate for a first-contact use case. When a clinician asks a RAG-based system for a summary of a patient’s most recent blood pressure readings, and they already know the patient has tachycardia from prior chart review, they are using RAG with a baseline mental model. They are looking for a targeted synopsis inside a context they already understand.
If a RAG-based system, on its own, starts emphasizing blood pressure patterns because it “realizes” the patient likely has tachycardia and then leans into that theme to create a richer story, it may be drifting into the realm of decision support rather than simple summarization. Traditional event-based summaries (e.g., discharge summaries, HPI) are written to give broad context about everything happening around the patient, with the HPI surfacing why certain diseases should be viewed as most pressing. Presenting every clinical fact in strict disease ontology order via AI has never really been how humans write summaries, and doing so for a patient the clinician has never met may have more decision impact than these systems should carry in the first pass, before the clinician has built their own cognitive map.
A reasonable design choice is to treat RAG as a powerful second-layer architecture: ideal for deeper chart digging once the clinician already has a basic longitudinal story, rather than the primary engine for the first AI medical record summary they see.
Once the pipeline for summarization is architected, you next choose what type of LLMs you use and how they are trained: i.e. models fully trained on your own dataset, fine-tuned LLMs, few-shot training, or zero-shot (aka prompt engineering).
Fully Training an LLM
Fully training an LLM has the potential for the best performance, but very few people in the world are actually trained and capable to lead a research team (and have the financial resources) to surpass the performance of the state-of-the-art models and justify not just using a fine-tuned approach. Fully training a healthcare LLM takes a large amount of data, and the parameter size of the state-of-the-art models today is extremely large – meaning you need to secure large amounts of GPUs to handle the volume of data and the time required to train. Running a model at inference is completely different from the GPU costs of training. We are talking about hundreds of thousands, if not millions, of dollars to train your own healthcare LLM.
It’s also unclear in 2025 if a fully trained LLM on only healthcare data is actually superior to fine-tuning a general-purpose LLM. Medically tuned models from large players (e.g. Google’s healthcare-focused Gemini/Med-PaLM family) have not shown a clear, consistent performance gap over top general models like OpenAI’s GPT-5.1 or Anthropic’s Claude family across all real-world tasks. So after you spend a pretty penny building your own LLM, and securing the top talent in the world to do it well, you may still find yourself wondering if it would have performed better to fine-tune with a subset of your data as the gold standard, at far less cost, and put your resources into alignment and evaluation instead of full pre-training. In the last two years, it’s increasingly unclear whether it is worth it anymore to build your own healthcare foundation model. A few companies, like Hippocratic AI and some large tech vendors, have tried to build healthcare-specific models, but smaller companies with far fewer resources are able to build approaches that are just as strong – if not stronger in practice – by fine-tuning or using few-shot approaches on top of the leading general-purpose models.
The reality is that model architectures have gotten so good for the base models that it is almost always better to borrow that model than to rebuild it from scratch.
Fine-Tuning a Model
A fine-tuned model is borrowing an existing LLM and aligning its performance to be more specific on your subset of data. You are slightly recalibrating the parameter weights for new documents it has never seen, so it can borrow its prior learnings. The LLM doesn’t have to re-learn the basic grammatical structure of English or how contextual documents are generally written. A fine-tuned LLM is helping it learn how to specifically write one type of document, like the discharge summary or a SOAP note, for instance. Fine-tuning the model well still takes serious ML talent - but you no longer need to be one of the maybe 1,000 people in the world who could realistically build a frontier model that competes with the dominant LLM families. Fine-tuning an LLM typically takes at least a few thousand high-quality labeled examples; and the fewer examples you provide, the more serious ML talent you need to avoid overfitting, bias, and unstable behavior. At Abstractive Health, we have built components of our workflow with fine-tuned LLMs using models like LLaMA 3 70B and sentence-based vectors.
Few-Shot and Zero-Shot Learning
Few-shot learning is how many gold-standard examples you provide directly to the base LLM inside the prompt. When you create a system prompt for your orchestration, you can provide a small set of examples that show the LLM what a “correct” response looks like. Numerous research papers have demonstrated that state-of-the-art models can become very accurate in specific domains with as few as 3-5 well-chosen examples. The number of examples given in the prompt is literally how many “shots” the model has to learn the specific pattern.
With few-shot learning, you are not re-wiring the model’s parameters; you are steering its behavior through examples. For many clinical summarization tasks, a few-shot prompting with a strong base model will outperform a poorly executed fine-tune, especially when you have fewer than ~1-2k labeled examples. In other words, if your labeled dataset is small, you will often get more reliable performance by treating those examples as in-prompt demonstrations rather than forcing a full fine-tune. You can, of course, combine both: fine-tune a model on your broader distribution of cases, and still use a few gold-standard examples in the prompt to tighten behavior for specific workflows.
Zero-shot learning is just using an LLM without any worked examples in the prompt. You are relying entirely on the model’s pre-training and a well-written instruction. “Zero-shot” is really just the standard LLM approach when people talk about prompt engineering without examples.
Hallucinations
Hallucinations in LLMs are often caused by their core architectural objective: next-token prediction. These models are trained with gradient descent to produce the most likely next token, conditioned on everything they’ve seen so far. They are optimized to give some answer rather than to give no answer. When data is fed into a prompt as labels, and when users interact with an LLM, the expectation is a factual response; the model is simply trying to produce the next token that best fits that pattern. Designing a system to reliably say “I don’t know” or to withhold an answer when it lacks sufficient information is actually quite challenging architecturally. Recent advances in state-of-the-art LLMs have shown that as base models become larger and better trained, hallucinations decrease overall. But even as we add more data and larger parameter counts, hallucinations remain an inherent by-product of that next-token architecture.
In general, the more abstractive (as opposed to extractive) the summarization task, the greater the risk of hallucination. Abstractive means you are asking the LLM to paraphrase and rephrase content, not simply pull key sentences directly from source documents. A good AI medical record summary balances how much paraphrasing is allowed in order to create a coherent narrative, while limiting it by design to remain medically safe for patients. Building a state-of-the-art AI medical record summarization system is first and foremost about balancing this architecture. Medical summarization needs to stay more extractive than many other domains, and clinicians strongly prefer produced content that is clearly sourced back to original documentation.
Building Trust Through Clinical Evaluation and Provenance
After you’ve built a full architecture for AI medical record summarization, it is critical to fully test it before rolling it out to clinical end users - ideally through an evaluative framework that you can publish in peer-reviewed literature. Because clinicians often have no prior cognitive understanding of a patient before they read an AI medical record summary, it is hard for them to provide granular feedback on accuracy in a live environment. The whole purpose of the tool is that they don’t have to review the full record and manually verify every sentence. Clinicians are operating with a baseline assumption that your tool “just works.” Releasing any AI medical record summarization tool without an initial, robust clinical evaluative study is reckless.
A beta phase for AI medical record summarization is ideal to iterate on the structure of the summary itself. Healthcare doesn’t have a gold-standard full-record summary format, so you want to validate that your orchestration is clinically accurate for your initial hypothesis, and then use a controlled beta with real users to tune the form of the summary - section order, level of detail, phrasing - without changing the safety properties underneath.
Because clinicians have less baseline knowledge of the patient before reviewing an AI medical record summary, they are also reviewing the content with perception bias. They will quickly form heuristics and impressions about a patient. If you don’t provide them with source note linking to confirm or challenge those impressions, they may perceive your summary as much less accurate than it actually is. Your AI medical record summary might be perfectly accurate, but if it reports two facts that seem unlikely to coexist in a typical patient (such as “severe hemophilia A with a history of recurrent DVTs on long-term anticoagulation”), the clinician is very likely to assume the model made it up rather than consider that both events might actually be true.
This is why we have found that AI medical record summaries almost always need sentence-level provenance. It is very hard for a clinician to know when an LLM is correctly reporting an unusual combination of events versus hallucinating. Without sentence-level provenance, you are effectively telling the doctor: “if anything doesn’t pass your sniff test, disregard it.” But the whole purpose of medical training is to recognize and investigate low-probability, high-importance events. We employ primary care doctors and not WebMD precisely so that, when presented with something that looks off, they can decide whether it is clinically meaningful and act on it.
At Abstractive Health, we’ve found that the entire product value is in enabling clinicians to dig into the chart and build those richer understandings, while giving them a better baseline map of the patient. The user experience - and specifically how easy it is to jump from a sentence in the summary to the exact source note - becomes critical to how the system is used in practice and whether clinicians trust it.
Trustworthy AI for Medical Record Summarization
Accuracy for AI medical record summaries has a two-step evaluation:
- computer-based metrics (ROUGE, BLEU, and factuality measures like dependency/entailment checks against the source), and
- clinician-based evaluation of a random subset of summaries for readability, coherence, factual accuracy, usability, and patient safety.
ROUGE scores measure how much overlap there is between the produced summary and a labeled gold-standard summary, usually in terms of n-gram recall. BLEU is a related family of metrics that focuses more on n-gram precision with a brevity penalty. Both come from the philosophy that a good summary should share a lot of overlapping phrases with a strong reference summary. There are many ways to write a narrative, but as a rough rule: the closer your output is to the reference, the better the score.
The weakness is that these metrics don’t directly measure hallucinations or clinical safety. In English, you can have two nearly identical sentences where a single word flips the meaning from correct to dangerous:
- “The patient has no history of diabetes.”
- “The patient has a history of diabetes.”
Lexically, these sentences are almost identical. ROUGE and BLEU will rate them as very similar. Clinically, one is a benign statement and the other is a major difference with huge implications for risk, medications, and follow-up.
So while ROUGE and BLEU are useful for catching gross performance issues and benchmarking “how close are we, on average, to a reference summary,” they are not ideal for measuring clinical safety, reliability, or real-world usability. AI researchers have proposed automated factuality checks that try to assess whether each claim in the summary is entailed by the source text using dependency structures or entailment models, but those methods are still imperfect. They can help you triage obvious problems, but they are not enough on their own to say, “this is safe for front-line care.”
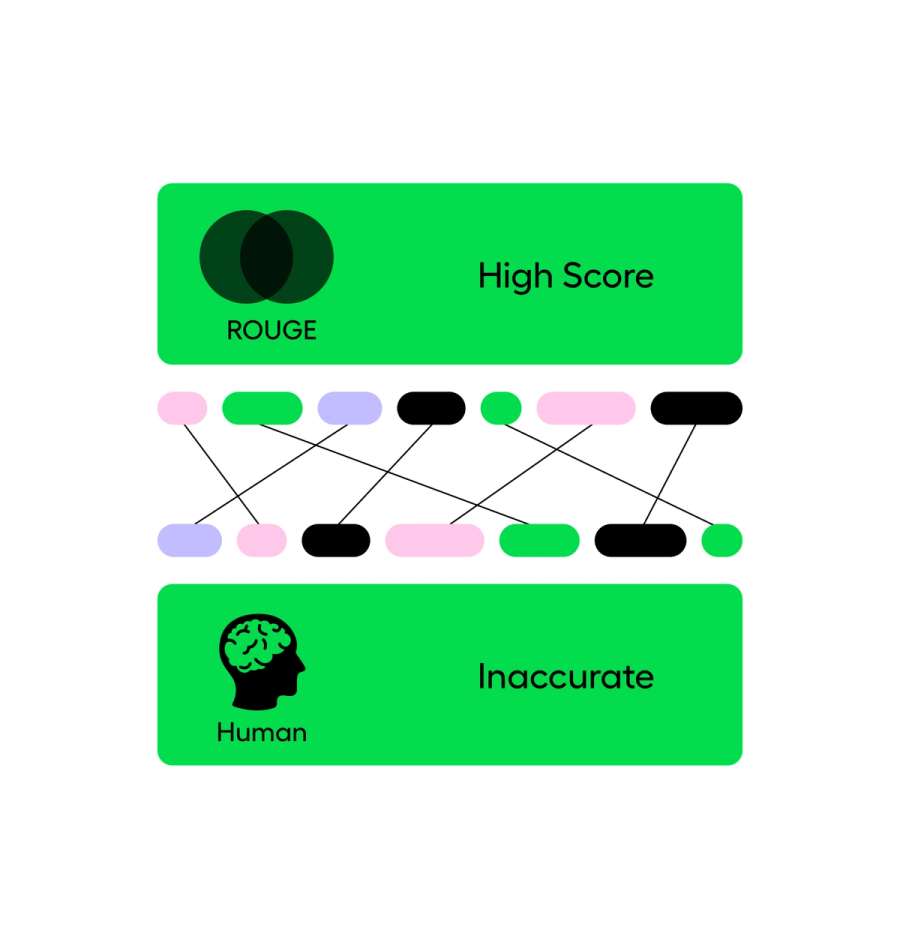
That’s where human evaluation comes in.
With a clinical evaluation of AI medical record summaries, you have a group of clinicians (at least two, often more) score summaries on Likert scales for quality, readability, factuality, completeness, and patient safety, and add free-text comments. Through this human evaluation, you can ask the right questions:
- Does the orchestration help clinicians find fewer errors than in human-written summaries?
- When there are errors, can clinicians quickly jump to the source documentation to verify them?
- If something is wrong or incomplete, how easy is it to correct or augment the summary?
Think of this phase as calibration and real-world alignment to edge cases. You’re not just scoring “how good is this in general”; you’re learning where the system breaks and how clinicians actually interact with it under pressure.
Humans are not needed to review every single summary and re-do the LLM’s work every time. That would defeat the purpose of AI medical record summarization. But humans are needed in a deliberately designed clinical assessment phase to verify that the system is working as intended before broader rollout. Without this stage, it’s essentially impossible to calibrate the system correctly. The nature of AI medical record summarization does not lend itself to the traditional “ship fast and fix it in production” software mindset. By the time an end user complains about something being wrong in a summary, the damage may already be done on the patient side.
For AI medical record summarization, sentence-level linking to source documentation isn’t a nice-to-have; it’s the backbone of trust. For every summary, you should be able to see:
- how a given sentence (or clause) was produced,
- what specific content was provided to the LLM to generate it, and
- what needs to be tuned in the orchestration or prompts to change that behavior in the future.
For every clinically meaningful sentence in an AI medical record summary, you should be able to pinpoint exactly where it came from in the chart. If you cannot do that, you don’t have deep reliability of the system’s performance over time, and you have no real way to audit or improve it when something goes wrong.
At Abstractive Health, we have performed three robust clinical evaluation phases of our software and published our research in peer-reviewed journals. We have also participated in the 2024 VA AI tech sprint where a panel of judges rated our summaries on a similar Likert scale and assessed the viability of our system. Among 200 companies, we ranked in the top 3 outperforming huge enterprise vendors. Our AI medical record system is one of the most clinically evaluated tools on the market. We deeply believe that AI trustworthiness is a core component of AI medical record summarization.
Importance of User Experience
The objective goal of an AI medical record summary is to serve as an orchestration, not as a replacement of patient record: reviewing the source information should better enable the clinical chart digging workflow. A summary as an orchestrator allows the doctor to quickly dig through the chart and find the most important information, it doesn’t replace the need to look at the original source content and perform fact finding. It also is not designed to replace the total amount of time the clinician spends learning about the patient before a visit: traditionally ~5 minutes before the walk into the exam room.
In order for a clinician to use a summary as an orchestrator, they need to be able to see the source notes side by side to the summary content. When they click on the summary, it should immediately take them to the location of first-order facts that were used to build the summary.
Likewise, when a clinician is reviewing an AI medical record summary, they expect the structure to be consistent. The layout, style, and design, should always be the same for every patient in the review. The goal is that as they read more and more of the AI medical record summaries, they are not spending any time getting up to speed on the contextual framework - just like a SOAP note or Discharge Summary, they have an inherent heuristic of how the document should be structured. And so, the AI medical record should always have the same sections, the same style within each section, the same formatting, and roughly the same length.
Even though the EHR system is the final document of record for many patient workflows, a lot of doctors prefer to first author their note in an ambient voice solution or in Microsoft Word. Building a good note-writing tool is a UI/UX problem, and EHRs have not been traditionally incentivized to enable good note-writing with the exception of adding templates.
Clinicians are highly incentivized to use EHRs because of Meaningful Use incentives and revenue return, they are often not choosing them because they are excited by the software. AI medical record summaries, designed for doctors, as the first point of care before a visit, is uniquely a clinical problem designed to improve the cognitive function of the doctor’s job. And so uptake of AI medical record summaries will be driven if doctors perceive greater happiness and cognitive understanding of their patients than the traditional EHR.
Clinical Workflows Most Interested
Historically, full medical record summaries mostly lived in an outsourced, highly specialized workflow: clinicians or nurses were paid hundreds of dollars per hour to create comprehensive summaries for medical malpractice cases, appeals, and compliance work. The main driver was simple willingness to pay; only use cases that justified $300–$500/hour of human effort could afford true full-record summarization.
Just as early scribing workflows followed the specialties with the highest willingness to pay (orthopedics, surgery, procedural subspecialties), AI medical record summarization has so far grown up around payor, claims, and non-clinical review workflows. Those stakeholders can justify the spend more easily than an individual primary care physician or small practice. It’s not that clinicians wouldn’t see better clinical outcomes and safety with an AI medical record summary—handoff and discharge summary research has repeatedly shown that high-quality summaries have a large impact on care enablement—it’s that economic incentives have pushed the first generation of products toward non-clinical buyers.
At Abstractive Health, we’re seeing the strongest pull from settings that live and die on a longitudinal understanding of the patient’s story: primary care and family medicine, hospice and palliative care, skilled nursing facilities, assisted living, geriatrics, maternal health, and fertility care. It’s not that hospitalists, specialists, or ED clinicians don’t benefit from AI medical record summaries; they do. But these longitudinal settings have traditionally lacked any standardized, reliable structure to build a cognitive map of the patient in the first few minutes of contact. That is the gap we are focused on closing.
AI Medical Record Summarization -> Patient Intelligence
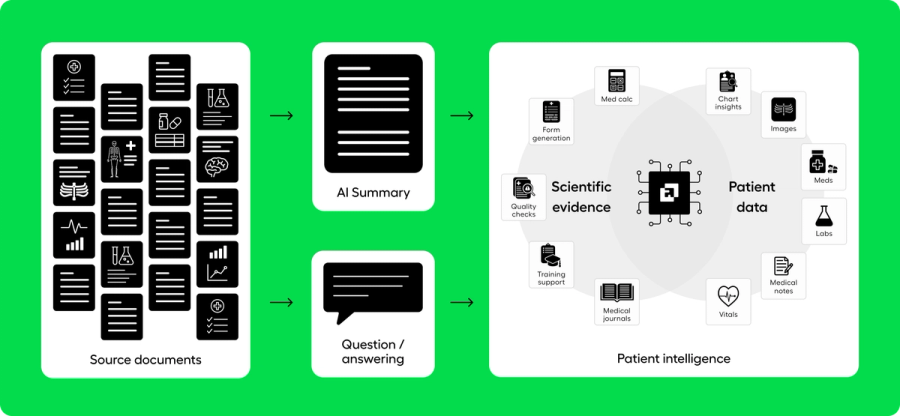
Clinicians regularly take on complex patients they have never met and have very little time to get up to speed on their health history. That cognitive onboarding step often happens before they meaningfully interact with the EHR. Patient intelligence is the foundational layer for that moment: it represents the first five minutes of care, when the clinician is building their initial mental model of the patient.
The core technology that enables patient intelligence is an AI medical record summary. Until the last two years, building a comprehensive AI medical record summary at scale was technically infeasible. LLMs now make it possible. EHRs were never built or incentivized to create intelligence from full records; they were built to assist with data collection, scheduling, compliance, and billing. They are excellent at order entry and record keeping - but the last 15 years have overwhelmingly shown that clinicians are clamoring for a deeper understanding of the patient record than what an EHR alone can provide. What they are really seeking is patient intelligence.
When all of the underlying pieces come together in a well-built AI medical record summary - paired with a question-and-answer RAG tool - our prospective simulation of patient intelligence has shown that clinicians can diagnose complex conditions in less than 12 minutes from scattered source documentation. We invite you to experience our simulation by reviewing the records of King George III and seeing how an AI medical record summary can be designed to guide a clinician toward patient intelligence.
In real-world use, we are seeing clinicians interact with our tool not as an “AI assistant” bolted onto the medical record, but as the first step before they enter the EHR and formally take on care for a patient. This layer of care - historically informal, with little oversight or standardization - is exactly where AI medical record summaries provide the most value, in a field most appropriately called patient intelligence.
Concluding Thoughts –
At Abstractive Health, we have under-the-hood built this full pipeline to create a magic that when you search for a patient record, we create a full longitudinal AI medical record summary linking to all their documents from across the country. And then you can ask deep questions on any of those records. The system is designed so that even independent clinicians of 1 doctor can use the system to understand their patient before a visit. Our mission is simple: empower clinicians with complete, accessible, and actionable patient data when they need it most. By delivering higher retrieval rates, requiring minimal inputs, providing faster access, and leading the field in clinically validated summarization, we’re helping clinicians make faster, safer, and more informed decisions on their patients.
Clinicians can sign up here and see our technology in action for free, with quick access to see it in action for the patients they care for.
Related articles
Importance of Sentence Matching with AI Clinical Summarization
How to Read and Summarize Scan PDFs in Medical Records
Accuracy of an AI-Generated Summary: A Deep Dive into ROUGE Scores
How to Write a Clinical Summary
Why is Summarizing so Difficult in NLP?
Extractive vs Abstractive Summarization in Healthcare
Related Articles

See the Abstractive Health AI assistant in action to discover what real efficiency can look like.
Try for freeStay ahead of the curve in healthcare innovation.
Connect
Abstractive Health
Resources
©2026 Abstractive Health. All Rights Reserved.
