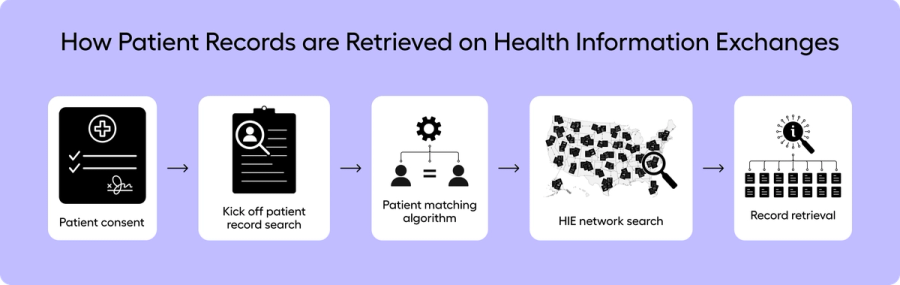
How Patient Records are Retrieved on Health Information Exchanges

by Vince Hartman
Nov 18, 2025
This is a deep explainer from Abstractive Health on how record retrieval actually works under the hood in the U.S.
Doctors can retrieve a patient’s full longitudinal chart within about 5 minutes; it’s quite a marvel of the US health system’s accomplishments in the last 15 years. In fact, the US has one of the most advanced interoperability systems in the world, with billions of exchanges occurring monthly. The interconnected pipes that keep the system working and running are quite a modern feat so that your doctor can have a deep understanding of who you are before a visit - and provide better care. And even though the system is fragmented, built with independent nodes, with no centralized database of records – the structure is actually more interconnected than systems like Canada, Australia, and the UK, and the US consistently outperforms those countries in record retrieval for clinicians to access treatment records.
Patient Consent
During the check-in process with your doctor, you are given a set of consent forms and notices for them to authorize treatment with you under Health Insurance Portability and Accountability Act (HIPAA). This privacy notice is known as the Notice of Privacy Practices (NPP). Often included in the NPP forms is a clause that your doctor has the right to retrieve your medical records with the national health information exchanges (HIEs) to better your care, and to share your record after your visit with the exchanges. State law is constantly changing on how HIEs must handle consent. Many states today treat participation in an HIE as opt-out or implied consent for treatment, but a minority of states - including New York and Florida - still require some form of explicit opt-in consent at the HIE level, and several others use hybrid models.
It’s fair to say that if you refuse the basic HIPAA framework, you’re basically refusing to be treated. The NPP is the terms-of-use for being someone’s patient: it explains how your information can be used and shared for treatment, payment, and operations. You can ask questions, you can object to certain kinds of sharing, and you can always choose another provider. But if you insist that a clinician care for you without being allowed to use your health information under HIPAA, you’re effectively saying you don’t want them to treat you at all.
And realistically, if you don’t want your treatment team to access your health information, you are severely limiting their ability to care for you. Doctors are trained - and ethically obligated - to use the best available information to avoid harm. Forcing them to practice “blind” by hiding key parts of your history doesn’t make you safer; it increases risk.
The HIE infrastructure is built on that same principle. These bi-directional connections exist to give a treating clinician a more complete view of your record when they have an actual treatment relationship with you. The default assumption in the U.S. system is not that payors, pharma, or random third parties are out there browsing your chart. The pipes are designed, first and foremost, so that another doctor who is actively taking care of you can get your record quickly enough to help you – and only in the context of that treatment relationship. That narrow, treatment-first use case is what has allowed the system to exist and maintain any level of public trust at all.
Patient Record Identification
Once the doctor has received your consent, they must now search for your record. The United States does not have a universal medical record number, so the search is performed on the aggregate of your demographics. The US almost created such a universal healthcare ID - and HIPAA in 1996 actually envisioned such an identifier to reliably track person records - but Congress actually banned any money or development of an ID system in 1998. Americans have a deep distrust of our government - in recent Pew polling, only about 22% of Americans say they trust the government to do the right thing, which means roughly 78% do not. Past abuses have shaped our distrust of a universal ID system such as Japanese internment camps, Tuskegee Syphilis study, and use of Henrieta Lacks’ cells without consent - all of which make both sides of the political aisle nervous for a medical record number.
Patient matching is typically done through an aggregated weighting system with principal weighting on your full name, date of birth, sex, phone number, and address. If provided, additional fields can enhance weighting such as middle name, maiden name, email address, and social security number. Social security numbers are generally not used anymore by healthcare providers given cybersecurity risks and fears of abuse.
Each implementer on the HIE system has built their own matching algorithm and is responsible for maintaining the logic, but many have built a framework using a Fellegi-Sunter-style probabilistic matching model. With this model, each field is given a set number of points, and once enough points have been accumulated, then the two patients are determined to be a match. For example:
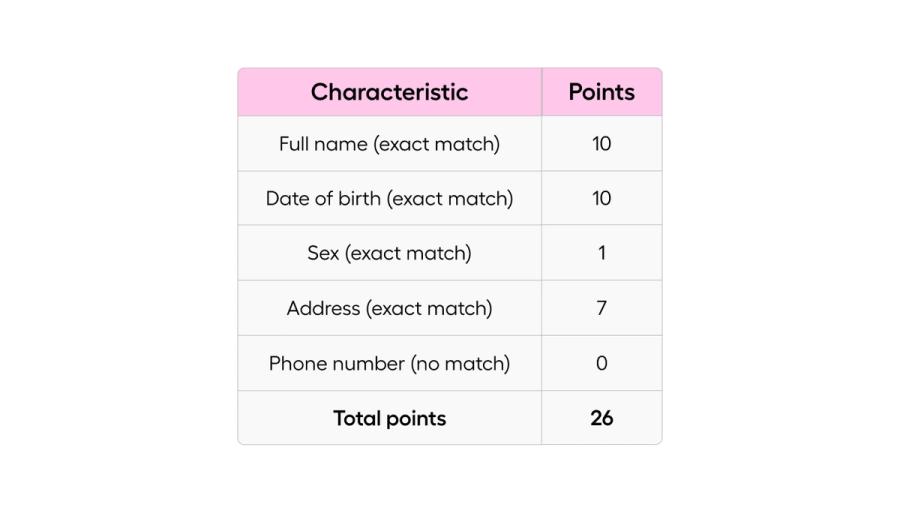
Once points have crossed a threshold of some number - in this example it would most likely be 20-22 points depending on the implementer, a message will be returned to the provider that performed the search that a patient has been found.
The matching logic is dependent on collecting a robust and correct composite of the patient - and so if at check-in the provider uses a nickname of the patient (e.g. Matt instead of Matthew), the name matching score will decrease. At any given time, there is likely 1-3% odds that even with the correct demographics provided, a match will not occur because of incorrect data stored between each system.
Likewise, to increase the odds of matching - a core component is to consistently have a USPS cleaned address. So instead of just passing the address that the patient provided during check-in - you first route the address to a service like Google Maps or a USPS API, for example, and you transform the address to the official one on record. So “123 main street apt 4b, nyc, ny” would be transformed to “123 MAIN ST APT 4B, NEW YORK NY 10025-1234.”
Furthermore, if you can retrieve all of the historical addresses where the patient has lived over their lifetime, you are able to then include those in your query to improve matching performance. Patient matching algorithms generally don’t penalize you for providing more information such as addresses or emails even if they differ from what the requesting system has on file (with the exception that the algorithm might penalize fields such as date of birth and sex if those differ).
Patient matching algorithms have been more or less highly optimized the last decade, so it’s in your interest to collect as much information from the patient, submit everything you have, and the system is more or less designed to provide matches back with a philosophy of more information is always better.
Record Retrieval
Using the patient’s prior and current addresses, at Abstractive we perform a geo-spatial record location search to find the organizations and providers that have treated the patient over their lifetime. Carequality, a non-profit consortium of fellow implementers, maintains a directory of all healthcare locations with available endpoints to query for patient records. The directory has more than 60k practices, so it’s unreasonable to query every single one for every search without creating an unnecessary burden on the ecosystem. When you query an implementer, they need to determine for every single request if there is a match or not, and each one is sustaining some level of transactional cost to maintain the throughput to handle thousands of requests per second from every member in the ecosystem. Furthermore, a lot of endpoints are maintained on a single implementer’s server and not distributed, so if you query thousands of times to the same implementer in ten seconds, they will be throttled anyway, as they are not designed to handle that level of traffic (that’s basically how DDOS attacks work).
Simultaneously calling hundreds of endpoints with low latency is a lot harder and more computationally complex than just calling one central server that informs you where records are located. CommonWell, a large HIE, has developed a national record locator service (RLS) that is designed to inform you where patient records are located and operates as a quasi-national matching database of patients. While calling an RLS can help optimize patient matching and throughput, it can have the unintended consequence of increasing latency. By using an RLS, you are structuring a system to sequentially call two services before you find the patient record (unless the RLS itself returns the found / not found message). If the RLS takes 20 seconds to respond with matched endpoints and you then call another endpoint to retrieve the patient ID for that endpoint that takes 20 seconds, you’ve extended your latency by 2x. In other words, you’re trading some latency for a simpler, more centralized matching step. EHR and API implementations on HIE systems have worked around this latency by building robust integrations with practices’ scheduling systems – when a patient checks in for the visit the night before their exam, the system will query that record in advance.
For small practices and medium-sized organizations that use EHRs without robust practice management systems – or don’t have development teams to set up API integrations into the national HIE structures – this has been one of the limiting factors. While the HIEs are able to find and pull records, the implementers are not held accountable for latency standards like “return full records in < 15 seconds.” Their systems have been optimized to return full records in ~2–3 minutes, with throttled throughput and data transfer of large byte packages of full records, and timeouts if you attempt to retrieve the full record set of thousands of notes at one implementer in quick succession.
Large organizations with scheduling teams can enable record retrieval so that when a doctor searches in their EHR system, the outside records “magically” appear in seconds. They have been conditioned through their search behavior to believe the retrieval is happening almost instantaneously at the time of that query. In practice, the EHR pulls those records within the timeframe of patient consent at check-in before the doctor performs their search (which almost always has a workflow time lapse of more than 15 minutes).
This latency makes it very hard for implementers working with small and medium practices, that do not have robust scheduling teams, to create that same sense of magic. The technological underpinnings of the requirements are set up to support the needs of larger organizations. Abstractive Health’s geospatial logic is basically giving small and medium practices a version of what large systems do with prefetch, but without needing deep integration to their scheduling system. We have significantly optimized our search to be one of the fastest performing with latency <5 mins on most searches; and have built a bulk upload activity for clinicians to retrieve a full schedule of up to 30 patients without needing deep API or scheduling integration.
Most patients receive care relatively close to home: about 80% of Americans live within 10 miles of their nearest hospital, and emergency visits typically occur within only a few miles of a patient’s residence. With Abstractive, we have set up a geospatial logic to query patients within a 100–150 mile radius of their current and prior addresses, with certain zip codes having a larger search radius (like Boise, Idaho) versus others (like Manhattan, NY). Using geospatial logic, we are able to limit querying to ~500 endpoints per request, and then we can find a patient 97% of the time on the national exchange.
The one exception is that patients younger than 18 years old have worse performance than adults. Consent laws work differently for retrieving demographics of minors, which means it can be more tricky to assemble a full patient record set if they have lived in different locations, or have visited children’s hospital locations over their lifetime such as Shriners or St. Jude that are outside their home address location. We have made efforts to optimize for pediatrics, but we recognize it is a much harder process. We bias toward regional children’s hospitals and prior address history as much as possible.
Parsing CCDA, FHIR, PDFs
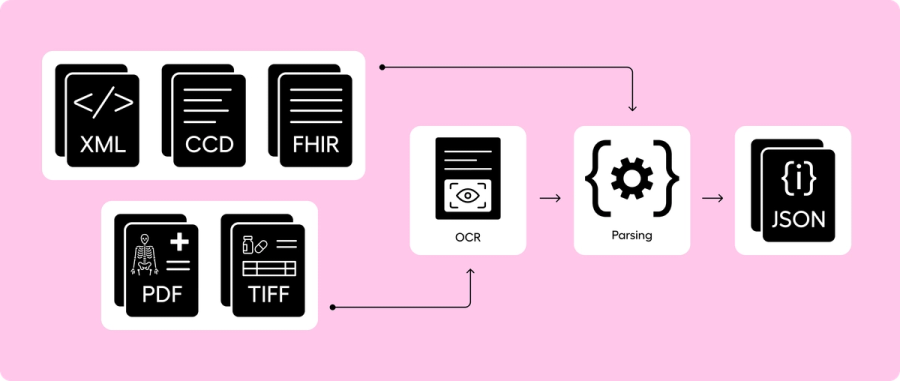
The search and retrieval component consists of three message types (ITI-55, ITI-38, and ITI-39) that go from (1) finding the patient, (2) finding the records, (3) retrieving the document content. When documents are returned on the HIEs to Abstractive, they are generally returned as a Continuity of Care Document (CCD) with a MIME type of XML. The CCD architecture (CCDA) combines both the structured and unstructured data of the patient visit - such as vitals, labs, healthcare providers, and clinical notes. The clinical notes in the CCDA are stored in a block of text without a coded medical ontology. And even though CCDAs have some structured content, the majority of useful clinical data is within the raw clinical notes.
CCDAs are pretty standardized, but FHIR is even more standardized and a newer framework. Before we feed any clinical data through our machine learning engine to make sense of the medical record, we parse every CCDA into a FHIR document. We have found that FHIR is easier to logically retrieve content from and communicate it to other external parties as needed. We subsequently take the FHIR documents and build our own JSON data structure to regroup redundant encounters, remove unnecessary wordiness, and collapse redundant medical codes. We perform a final cleansing layer and build our own JSON as FHIR still has too many tokens and too much structure when feeding into our large language model (LLM) stacks. In Abstractive, we make available for download the original CCDs, our parsed FHIR, and our own JSON data structure.
The remaining ~30% of the documents we receive on the exchange are PDFs, TIFFs, and images of x-rays. For these documents, we send them through an OCR parsing engine to pull the narrative text from the document so the text can be used for summarization and querying. Without an OCR component, the text on the documents would not be discoverable. And as ~30% of documents are not returned in the CCD framework, it’s a baseline requirement to parse these documents to ensure a complete longitudinal story of the patient. Otherwise a potentially significant component of the patient’s medical history is not easy to locate.
Parsing all of the raw medical content into clinical text that can be understood - without data loss – is essential to performing any AI logic on top of it. Almost all EHR systems have only been built to perform AI and rules on the structured content of a medical record. If you perform a search in the EHR, it will exclude deep reasoning on the raw clinical notes and the PDF scans. Querying a simple question such as, “what is the patient’s most recent blood pressure reading?” is just not easily possible, as you are not guaranteed that you will actually retrieve the latest value - it could have been written in a scan or the unstructured content of the note. This is why a doctor ends up chart digging through numerous notes, performing various clicks, to find that value. EHRs were optimized for structured data (an accounting database of every action performed in healthcare to meet audit and compliance standards). Abstractive Health was fundamentally built from the ground up to make sense of unstructured data so clinicians can get deep patient intelligence on their records.
AI Medical Record Summarization & RAG

Once all the records are parsed, we perform AI medical record summarization using a section-to-meta LLM pipeline and then structure the results for retrieval augmented generation (RAG). Our method for AI medical record summarization was developed over three years of research while in graduate school at Cornell University with Weill Cornell Medicine, using a baseline framework of the discharge summary. Healthcare doesn’t have a standardized “summary of a full medical record,” so we’ve had to iterate through a combination of medical research, deep customer feedback, and summarization competitions, including the 2024 VA AI Tech Sprint where we placed 3rd.
Our philosophy is that (1) the medical record summary should always be consistent, and (2) every underlying note should start with an equal footing for determination of importance and inclusion. Medical records can have a word count above 1 million, and so a true longitudinal narrative requires a deeper framework than just feeding all of the medical notes into a generally trained model.
The framework we’ve landed on that can handle the full record is a section-based modeling approach. We first summarize the content of every individual document, and then create a large meta summary from the set of individual document summaries. Through this structure, we are able to link every sentence back to the underlying source document, guarantee high levels of consistency (if we feed the same document set through the summarization pipeline multiple times, a near equivalent summary is produced), identify how inaccuracies and failures occur because we know exactly which document they originated from, and condense a huge amount of words into the token limits of current high-performance LLMs.
One of the limitations of our orchestration is that, for our baseline full medical record AI summary, we don’t allow the clinician to alter the prompt. The reason for this restriction is that we can only guarantee the accuracy and performance of our summaries because they have been rigorously tested over years and refined through carefully engineered prompts and fine-tuned LLM structures. So while other companies may offer clinicians the ability to modify the internal prompt, they are inadvertently allowing a non-validated summary to propagate to clinical users without deep testing.
Philosophically, we are ok if subsequent questions and answers are performed on medical records after a clinician has gained a baseline medical knowledge of a patient via a well validated summary. But AI medical record summarization itself should be deeply controlled, as it has too much initial impact on building the mental framework of the clinician.
Another internal debate we’ve had is: if our summarization pipeline fails to summarize one document or one section, (1) should the system gracefully fail where the summary is still produced but that one content block is left out (and the user is informed), or (2) should the system be treated as a critical failure stack and the whole summary is not returned, even though most of the summary was produced? We have built our summary stack as a critical failure stack that mirrors how a flight system on a plane would work. When a doctor reads our AI medical record summaries, they often have no mental starting point of the patient, and so if the summary leaves out critical information that is available in the record we retrieved – but, for instance, we weren’t able to parse the social history section because of an internal parsing failure or our guardrails triggered it as a failure – then we set the full summary as a total failure. That’s not how most AI works, but it’s how we determined AI medical record summaries should be structured.
During the creation of an AI medical record summary, we simultaneously chunk all of the documents into smaller sections of vector embeddings. We then store these vectors in a separate database designed for deeper retrieval analysis. Once the documents are vectorized, we enable a RAG system in Abstractive so that when a clinician asks a question, they are querying over the full record built on a temporal graphical structure of the AI medical record summary. And since each chunk is indexed back to the main document, retrieved content is linked back to the original documentation when a clinician asks a question.
At Abstractive Health, we have under-the-hood built this full pipeline to create a magic that when you search for a patient record, we create a full longitudinal AI summary linking to all their documents from across the country. And then you can ask deep questions on any of those records. The system is designed so that even independent clinicians of 1 doctor can use the system to understand their patient before a visit. Our mission is simple: empower clinicians with complete, accessible, and actionable patient data when they need it most. By delivering higher retrieval rates, requiring minimal inputs, providing faster access, and leading the field in clinically validated summarization, we’re helping clinicians make faster, safer, and more informed decisions on their patients.
Clinicians can sign up here and see our technology in action for free, with quick access to see it in action for the patients they care for.
Related Articles
Setting the New Standard for Record Retrieval and Summarization
Can Doctors Access Anyone’s Medical Records?
Why the Continuity of Care Document Is Not Effective for Transition of Care

See the Abstractive Health AI assistant in action to discover what real efficiency can look like.
Try for freeStay ahead of the curve in healthcare innovation.
Connect
Abstractive Health
Resources
©2026 Abstractive Health. All Rights Reserved.
